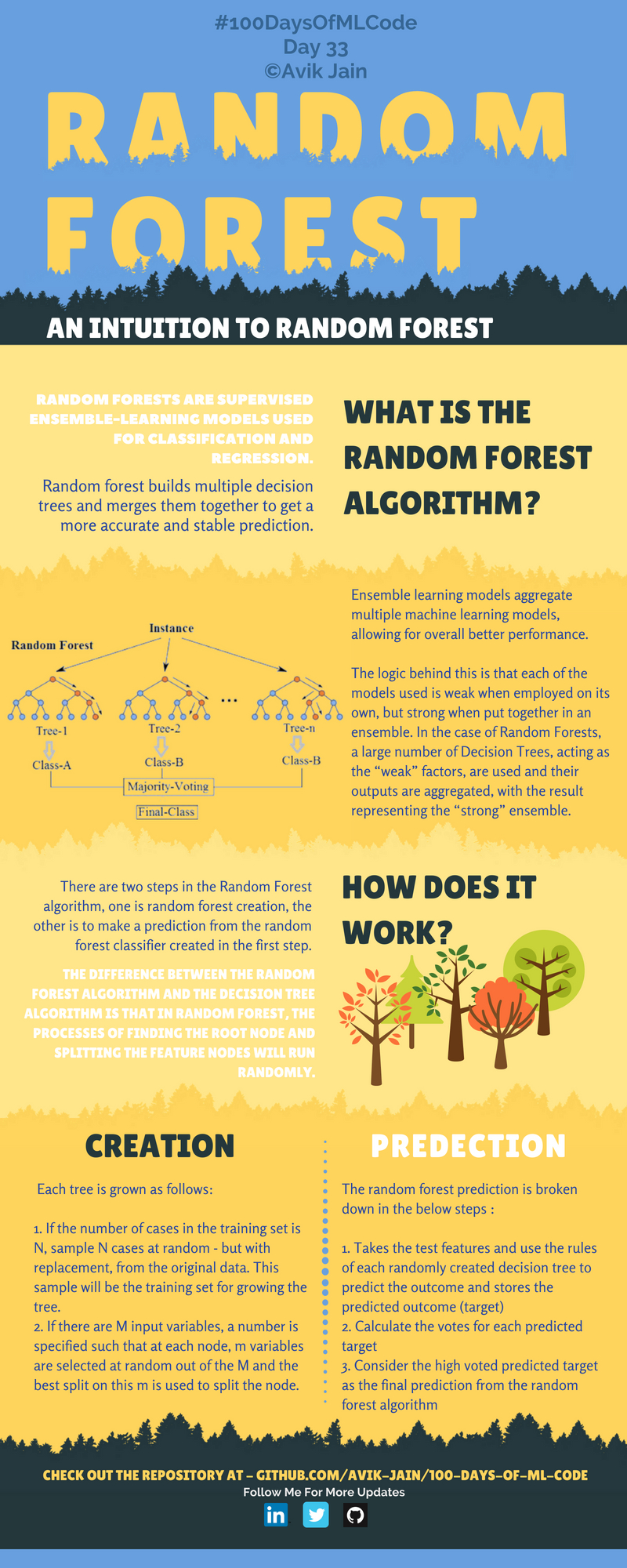
랜덤 포레스트
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # 독립 변수 (나이, 예상 급여)
y = dataset.iloc[:, 4].values # 종속 변수 (구매 여부)
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 75% 훈련, 25% 테스트
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train) # 훈련 세트에 스케일러 학습 및 적용
X_test = sc.transform(X_test) # 테스트 세트에 학습된 스케일러 적용
훈련 세트에 랜덤 포레스트 피팅
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0) # n_estimators: 트리의 개수, criterion: 분할 품질 측정 기준 ('entropy'는 정보 이득), random_state: 난수 시드
classifier.fit(X_train, y_train)
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
훈련 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('랜덤 포레스트 분류 (훈련 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()
테스트 세트 결과 시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('랜덤 포레스트 분류 (테스트 세트)')
plt.xlabel('나이')
plt.ylabel('예상 급여')
plt.legend()
plt.show()